In the last year we've seen a few agentic development tools being released, but most of them have been proprietary so it hasn't been easy to work out what's going on inside them. I figured it would be interesting to build something open source and to help me understand them better.
A lot of software engineers love terminals and I'm no exception (I have 6 open as I'm writing this), so I thought an agentic terminal would be fun to explore!
I wanted to enable both an AI and a human user to be able to interact with a terminal, run commands, and check results. This would give the human user an assistant to help with tasks in the terminal, but would also allow the AI to come up with creative ways to help meet user requests where using shell commands would be a good way to help.
In this post, I'll walk you through how I went about building this, why I built it the way I did, and how I used AI to help do this more quickly.
Getting started
An agentic terminal is a fairly simple concept. The core idea is we have a conversation interface that lets us discuss what we want with an AI, and this must be connected to some sort of terminal emulator and shell that the AI can use to run commands in response to our wishes. When a command completes, the AI must be able to look at what happened in the terminal emulator and decide what to do next (e.g. run more commands, or talk to the user).
To bake this "cake" we need some ingredients:
- A terminal emulator
- An AI conversation engine
- Some tools/functions that will connect the pieces
Fortunately for this problem, I already had the first two and a pretty good framework for the third one.
For the last year I've been building an open source AI environment called Humbug. It started out as an AI IDE concept, but it has been transforming over the last few months into something that is starting to feel more like an operating system. You can find the code on GitHub at: https://github.com/m6r-ai/humbug, and it's free under an Apache 2.0 open source license.
The code is currently all written in Python (about 65k lines of code at this point). It's also pretty-much dependency free. It uses PySide6 and qasync for the GUI, and it uses aiohttp and certifi for HTTPS connections to LLMs. Other than these, the only other dependency is the Python standard library. Deciding to minimize dependencies was to help both me and LLMs understand exactly how everything works, but it also means it's easy for you to see how everything fits together.
I could have built a stand-alone agentic terminal, but I wanted this one integrated with Humbug so I could leverage all the other things it already does. If you feel inspired to build a stand-alone version, however, most of the pieces inside Humbug are designed to be able to be extracted, so that should make it fairly straightforward.
A terminal emulator
The terminal emulator in Humbug took a couple of weeks to build but has some helpful design features. It has a clean separation between the emulator core, the GUI that renders it, and either a Unix shell or Windows command prompt that it connects to.
This means there's an in-memory representation of the terminal display (and scrollback buffer) that's used to display it in the GUI, but that can also be used to show an LLM what's going on. In the opposite direction it means there's a clean path for the GUI to inject key presses and we can leverage that for an LLM to do the same.
I don't claim it's a perfect terminal emulator but it passes all the tests I could find, and it runs both vi, mc and lazygit so it's pretty reasonable.
The design of the terminal emulator wasn't a lucky accident. I'd anticipated wanting to run the terminal emulation "headless" at some point - essentially what we need here. In this case we still display the terminal so the user can see what's going on as well as the LLM, but that's just a convenience for humans.
The backend code is in src/terminal, while the GUI in in src/humbug/tabs/terminal.
An AI conversation engine
An agentic terminal needs a way to let a user and an AI talk about what the AI needs to do. For this we need some sort of conversation engine.
We could try to somehow make our shell agentic but that would get very confusing because it would now contain a mixture of conversation and commands.
Humbug has a fairly sophisticated conversation engine that can also do a few nice tricks. For example it's possible to start a conversation with one LLM and then switch the conversation to another mid-way through.
As it doesn't rely on vendor LLM libraries it also has a unified abstraction over conversations so they can be switched between providers. This isn't a huge deal for our agentic terminal, but does mean we can do some interesting things with it. For example we can start a conversation with an AI and then have it fork the conversation to a different AI and have both of them try to solve the same agentic problem at the same time (and we can pick the best solution).
As with the terminal, the code has a useful separation between the backend LLM interfaces (Anthropic, DeepSeek, Google, Mistral, Ollama, OpenAI, xAI, and Zai), the asynchronous conversation engine, and the GUI. The async engine also makes it easy to have many different conversations running concurrently.
There's nothing particularly magical about this code, but it means we have a convenient framework to connect users and AIs. It does support AIs talking to other AIs which is a useful at times. For example, this allows our agentic system to spin up other LLMs to do research work if it's not sure about something (the advantage is the second AI doesn't pollute the context window of the first while it works).
The backend code is in src/ai and src/ai_conversation_transcript, while the GUI is in src/humbug/tabs/conversation.
Tools
An agentic terminal needs to have a way to connect an LLM to a terminal emulator. For this we need to give it some tools.
Tools are the glue that binds our deterministic software to our LLM. To interact with a terminal we need to send keystrokes to it, and receive updates on how the terminal display changes. It's also useful to be able to find out some metadata about the terminal too (e.g. its dimensions).
Humbug doesn't have a huge number of tools, but the ones it does have are very useful. It can read and write the filesystem (although this is sandboxed), can calculate mathematical results, has a clock, can delegate tasks to other LLMs, and can control some of the GUI.
The tool framework was designed to provide a user-controlled authorization for potentially dangerous operations and this is enforced by the tools and not the LLM. This means an LLM can't bypass the safety mechanism. We need something like this if we want to avoid an LLM doing "unfortunate" things with the agentic terminal. Tool approvals are integrated with the conversation engine and GUI.
The tool approval flow is quite simple. The python code in each tool decides if the operation being requested may have dangerous consequences. If it doesn't then the code will auto-approve the tool call. If the operation is attempting to do something the tool will not support (e.g. writing outside a project mindspace) then it will be auto-rejected. For anything else it will ask the user via a callback into the GUI.
Humbug already had tools to give LLMs some control over the GUI. The original "system" tool let it open different types of tabs, move them, and close them. This was a fun trick, and you'd sometimes see an LLM open an editor tab to show you something it had just written. This did mean, however, there was already a tool that could create terminals and get a unique identifier for each one.
The backend of the tool code is in src/ai_tool while the system tool is in src/humbug/system_ai_tool.py.
Putting it all together
Our ingredients are useful, but we need a recipe to put them together in a useful way. Enter AI (Claude Sonnet 4 in this case)...
When I start design work with an LLM, my default approach is to explain the problem I'm trying to solve and then discuss it until we have a design that makes sense. This is pretty much like I'd do with a human teammate.
In this instance, here's how I started the design conversation:
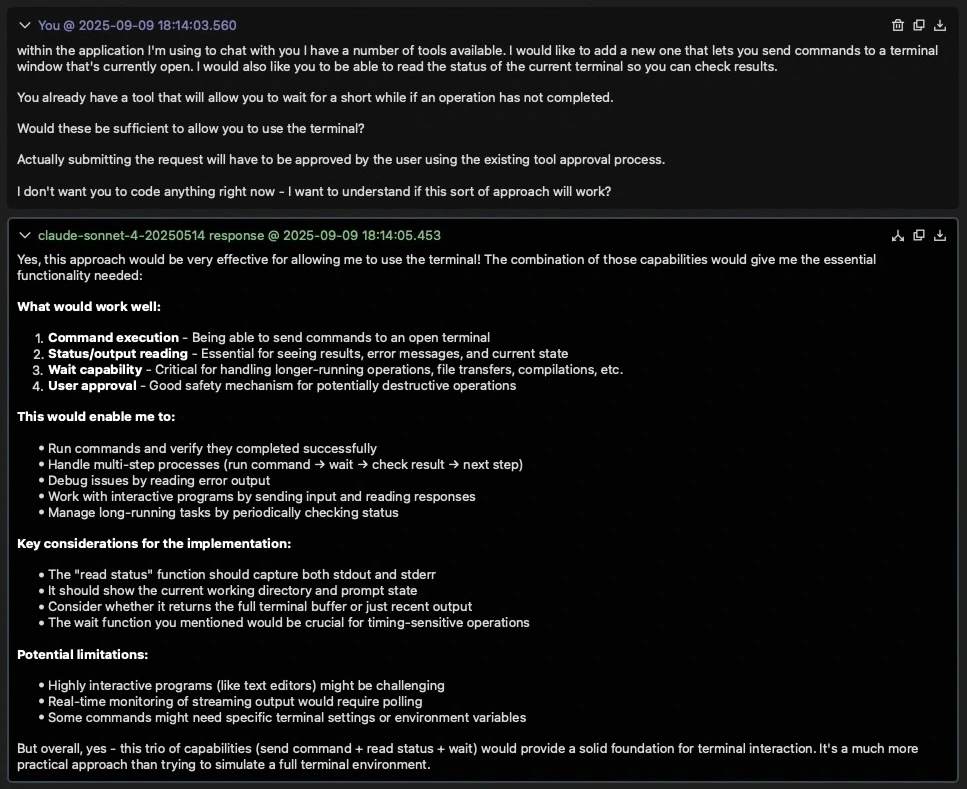
Within the application I'm using to chat with you I have a number of tools available. I would like to add a new one that lets you send commands to a terminal window that's currently open. I would also like you to be able to read the status of the current terminal so you can check results.
You already have a tool that will allow you to wait for a short while if an operation has not completed.
Would these be sufficient to allow you to use the terminal?
Actually submitting the request will have to be approved by the user using the existing tool approval process.
I don't want you to code anything right now - I want to understand if this sort of approach will work?
The first paragraph set up the problem I wanted to solve and how I'd like it to be solved. I drew the AI's attention to something it should probably consider (the sleep tool). Next I asked it to think about whether what I suggested would let it achieve my result. I added another note about needing to use tool approvals. Finally, and very importantly, I told it not to try to build anything yet - I just want to chat about the concept.
This last point makes a huge difference because it causes the AI to engage in a conversation. It gives it an opportunity to come up with ideas, explain them, and to ask clarifying questions.
Significantly, at this point I'd not asked it to look at any code. This was an abstract discussion about an idea.
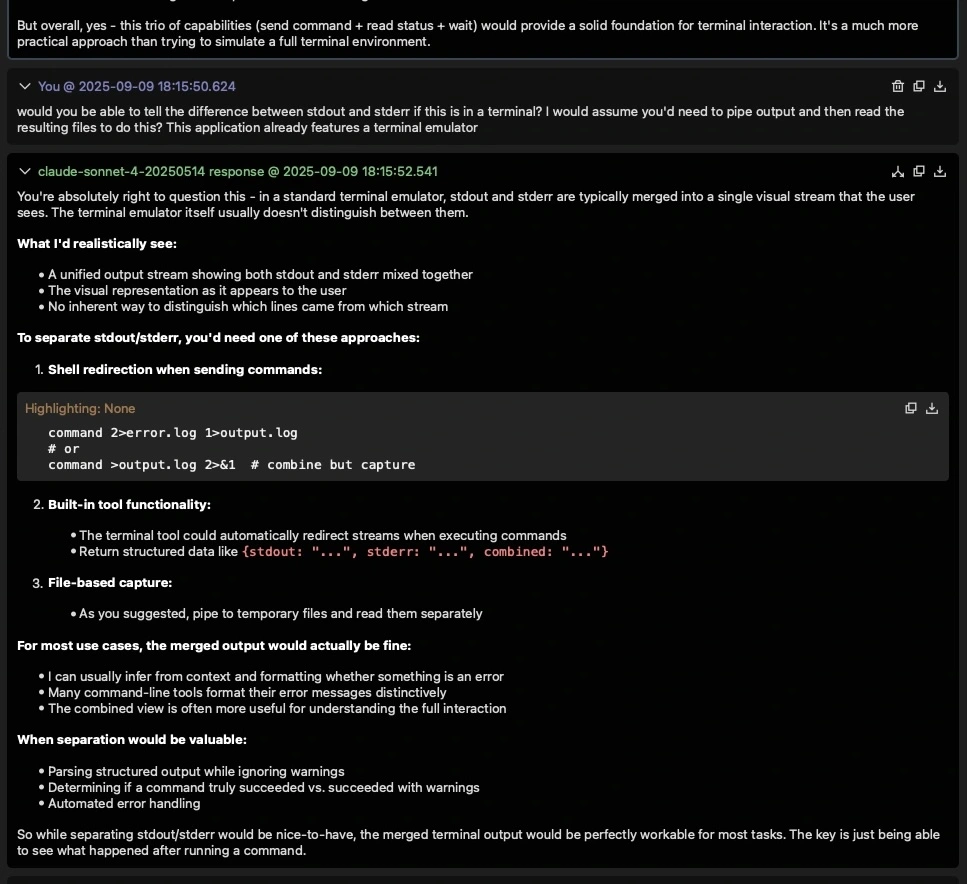
What's interesting is after this first round of conversation, the AI was slightly off course. It wasn't its fault - I'd been too vague. Fortunately, however, we'd not yet really designed anything so I could steer it back on course:
At this point things were looking much better, so I told it to go and start reading some code:
ok - great. You can see details of the terminal emulator in src/terminal. The UI for the terminal is in src/humbug/tabs/terminal
As Humbug has a filesystem tool it was able to read docs and source files as required and start to sketch ideas for an implementation. For brevity I've not included all the back-and-forth discussions, but in each case we worked on refining ideas and with me pointing out where the LLM could find more of the components it needed.
After about 12 minutes we got to a solid-looking design idea, and we were getting towards a good implementation plan:
<An aside about architecture>
I want to briefly make a comment about the importance of architecture.
An important aspect of this work was letting the AI work out what it needed to look at so it could build the necessary code. As Humbug doesn't have a lot of dependencies it makes it pretty simple for an LLM to find any code it needs, just as it did here. Over the last 12 months I've found the hallucination rate for code inside Humbug has been close to zero as long as the relevant source files have been able to be brought into the LLM's context window. By contrast, I've had some problems with PySide6 because the LLMs didn't have that same visibility. Instead, I've seen LLMs try to use what they predict will be supported by that library (based on probabilities), rather than what it actually does.
A key part of this has been to aggressively refactor Humbug's code to keep internal dependencies clean. I even added a custom checker tool, a few days ago, to prevent pollution between the 9 top-level source modules.
A few years ago I read (unfortunately, I forget where) that we can view architecture as a form of compression. In abstracting things we make it easier for people to understand how things fit together by giving them a higher-level view than the low-level implementation. I believe this is even more important when we're working with our current generation of LLMs.
Unlike humans, our current LLMs don't learn through recent use. They constantly need to be presented with accurate maps that allow them to navigate complex problems that exceed their context windows, because each new problem we present is as if it's the first time the LLM has ever seen it. They read very fast, but they're reading from scratch every time we hit "submit".
Architecture is important for humans. It's essential for LLMs.
</An aside about architecture>
At around the 19 minute mark we got a first version of the new design and then after reviewing the code I set it on its first task: checking the new code to ensure it had the correct type hints.
Claude is my go to model for building software, but it does take shortcuts at times. I tend to look for these with mypy and pylint. Previously I'd have gone through a manual process of running them, but in this very first run that ceased to be necessary. I was able to restart the application with the new code present and now ask it to run mypy. That was all it needed to detect some problems, fix them, and then recheck.
For perspective, getting to this point took about 30 minutes. This was a pretty impressive first example of the agentic behaviour I was looking for. To write my notes, fix some linter issues, tighten up parameter validation, and improve the tool descriptions added another hour. This represented about 450 lines of new commented code.
Polishing the implementation
New software is never straightforward, and I discovered a couple of things I'd not anticipated.
I ran into one problem with control characters when I tried to get an LLM to use vi interactively. LLMs don't emit control characters so they have to represent them as text, but we needed to come up with a way that they'd be very unlikely to use normally. LLMs are now told to emit \u#### format for this.
Another tricky part was getting gpt-oss:120b to understand that the terminal could be used to control interactive tools (vi in particular). We often talk about the importance of function and variable naming for humans, but it turns out LLMs can get confused the same way (probably because they're trained on our mistakes).
The original implementation called the operation to write to the terminal write_command, but this led gpt-oss to decide that was only for sending commands, and wasn't for sending keystrokes. This wasn't helped by a command parameter name. Renaming these to write_terminal and input went a long way to improving things.
A variant on this theme was gpt-oss:120b was convinced it couldn't use the terminal interactively because an unrelated tool (the filesystem tool) mentioned a sandbox. It took this to mean everything was sandboxed, so I had to update the filesystem tool description to make the type of sandboxing clearer.
I've always erred on the side of making Humbug's tools small and orthogonal to try to avoid LLMs becoming confused about which one to use, but this is more art than science. I suspect some problems I've seen reported with MCP (in other tools) may be down to this same type of combinatorial problem.
What do the tool operations look like?
I won't include all the code here, but you get something of a flavour by seeing the 4 tool operations associated with terminal tabs:
"new_terminal_tab": AIToolOperationDefinition(
name="new_terminal_tab",
handler=self._new_terminal_tab,
allowed_parameters=set(),
required_parameters=set(),
description="Create a fully interactive terminal tab. "
"This provides a terminal emulator connected to a new shell. "
"You may interact with this terminal using the `read_terminal` and `write_terminal` operations, but"
"you must use `read_terminal` to observe any changes."
),
"write_terminal": AIToolOperationDefinition(
name="write_terminal_input",
handler=self._write_terminal,
allowed_parameters={"tab_id", "input"},
required_parameters={"tab_id", "input"},
description="Write input to a terminal tab, given its ID. "
"This will be processed as a series of interactive key strokes. "
"You must use `\\u####` format to send any control characters (ASCII values less than 0x20)"
),
"read_terminal": AIToolOperationDefinition(
name="read_terminal",
handler=self._read_terminal,
allowed_parameters={"tab_id", "lines"},
required_parameters={"tab_id"},
description="Read the current terminal buffer (ouput display) content, given its tab ID. "
"This returns the raw content of the terminal display"
),
"get_terminal_status": AIToolOperationDefinition(
name="get_terminal_status",
handler=self._get_terminal_status,
allowed_parameters={"tab_id"},
required_parameters={"tab_id"},
description="Get terminal status and process information, given its tab ID"
)The new_terminal_tab was modified to reflect the new operations and give some guidance on how to use the 3 new commands. It's likely the descriptions may evolve a little with use.
One thing worth noting is the description for write_terminal now includes the control code directive.
Here's what I hope you take away from this
Starting with conversation is way more effective than starting with code. This lets you and the LLM explore a problem and get clarity before the implementation gets in the way.
Architecture matters. If you don't understand the code you can't engage in these sorts of discussions. Engineering is a discipline that allows a shared understanding between humans and LLMs. If a design is cluttered and confused then that understanding will not emerge.
As the joke goes, "there are 2 hard problems in computers: cache invalidation, naming things, and off by one errors". Naming really does matter though. LLMs are not like compilers and interpreters, and will use names as hints, just as humans do.
Beware unexpected interactions. If descriptions are ambiguous then we can see what look like innocuous statements in one part of a context window having unexpected impacts in another part.
Agentic systems are pretty cool but need a different thought process to conventional software. They're a little tricky to build because they're not predictable in a way we're used to seeing with computers in the past. Getting them to do things consistently is like working with people. Some people may "get" something immediately, others may need it explaining a different way.
LLMs can compress the time to build a body of code very significantly. The work I got done in 30 minutes would probably have taken me a day or more by hand, but once we got into the subtle issues my LLMs just become a sounding board, albeit one that can look things up for me very quickly. Achieving polished results may well become the new limiting step in software development because we've not accelerated that part very much yet.
I wouldn't say the agentic terminal is perfect yet, but it now seems to work pretty well!
If you're interested in the design, why not take a look. The Humbug project page has links and more information.